Predicting Lung Cancer Risk at Tikur Ambesa Hospital
Overview:
Analyzed clinical and lifestyle data from over 1,400 individuals at Tikur Ambesa Hospital in Ethiopia to identify key risk factors associated with lung cancer. The project aimed to support early detection strategies by building a K-Nearest Neighbors (KNN) model for severity classification and uncovering influential health and behavioral variables.
Tools & Technologies:
Google Colab, python, scikit-learn, pandas, numpy, matplotlib, KNN
Background:
Lung cancer remains a leading cause of cancer-related deaths globally. In low-resource settings, identifying risk factors early can greatly reduce diagnostic delays and improve outcomes. This datathon aimed to use patient-level clinical and behavioral data to explore which factors are most predictive of lung cancer presence and severity.
Research Questions:
1. Can we predict the severity level of lung cancer (healthy, low, medium, or high) based on patient-level risk factors such as smoking, obesity, and lung disease?
2. Which features are most strongly associated with severe lung cancer?
Rationale:
By applying machine learning techniques, this analysis leverages historical data to forecast lung cancer severity at both population and individual levels. These predictions can guide proactive diagnostics, enable earlier interventions, reduce healthcare costs, and ultimately save lives, aligning with critical public health priorities. Using a K-Nearest Neighbors (KNN) classifier, the model supports proactive diagnostics and intervention strategies that could reduce lung cancer morbidity and healthcare costs in low-resource settings.
Dataset:
Source: Tikur Ambesa Hospital, Ethiopia
Size: 1,465 observations
Features (12 total):
Age, Gender, Smoking, Passive Smoker, Alcohol Usage, Obesity, Air Pollution, Lung Disease, Genetic Risk, Chest Pain, Coughing up Blood, Severity
Target: Lung cancer severity (multi-class: healthy, low, medium, high)
Encoding: All categorical variables were pre-encoded (binary or ordinal)
Missing Data: None
Data Pre-Processing & ML Modeling:
Data Engineering
The dataset required minimal preparation. There were no missing values, and all columns were retained due to their clinical relevance. Categorical variables were already numerically encoded (binary or ordinal), and no additional feature engineering was necessary. The dataset included 1,465 observations across 12 features representing key lung cancer risk factors.
Exploratory Analysis & Modeling Approach:
We used Pandas and Seaborn to explore variable distributions (e.g., age, sex) and examine class representation across lung cancer severity levels. The K-Nearest Neighbors (KNN) algorithm was selected for its simplicity, effectiveness on labeled datasets, and efficiency with small to mid-sized data. A 70/30 training-test split was applied to support robust model validation.
Feature Selection & Importance Analysis:
To understand which features most influenced the model, we used Permutation Importance. This method shuffles individual feature values and measures the resulting decrease in model accuracy. It offers an interpretable view into each variable’s contribution to lung cancer severity predictions.
Results:
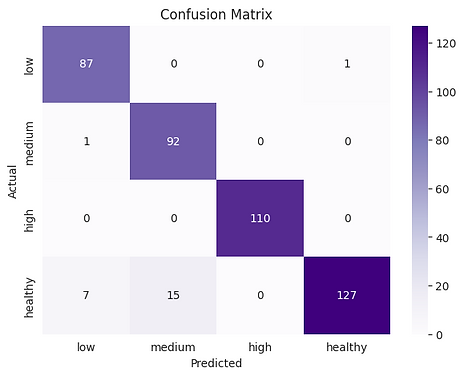

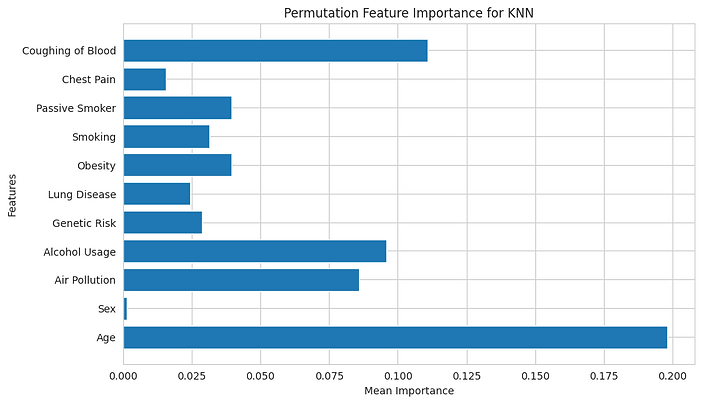
To explore lung cancer risk stratification using patient data from Tikur Ambesa Hospital in Ethiopia, we trained a K-Nearest Neighbors (KNN) classifier on 1,465 patient records categorized by disease severity. Our goal was to predict lung cancer severity and identify the most influential risk factors to guide early diagnostics and intervention.
Can we predict the severity level of lung cancer (healthy, low, medium, or high) based on patient-level risk factors such as smoking, obesity, and lung disease?
The KNN model achieved strong performance across all severity classes, with an overall accuracy of 95% on the test set. The model performed particularly well at the extremes of the severity spectrum. Notably, it achieved perfect precision and recall for the high-severity group, meaning no high-risk patients were missed, which is a critical outcome for clinical triage. The low- and medium-severity categories were also predicted with high accuracy, with F1-scores of 0.95 and 0.92, respectively. Healthy individuals were identified with a precision of 0.99 and recall of 0.85, reflecting a small number of false positives and some overlap with mild cases.
To understand which features most influenced the model, we applied permutation importance analysis. This revealed that age was the most impactful predictor. Shuffling this variable caused a 19.8% drop in model accuracy. Clinical symptoms, particularly coughing up blood, followed closely, with an 11.1% accuracy reduction when permuted. Alcohol usage and air pollution exposure were also strong predictors, with a notable effect on classification accuracy. In contrast, sex and chest pain contributed very little to model performance, suggesting a limited role in stratifying severity in this dataset.
These results highlight the potential of simple, interpretable models like KNN to support early cancer screening strategies, particularly in resource-constrained settings. The model's high recall for serious cases and identification of key modifiable risk factors such as alcohol consumption and environmental exposure align with public health goals for targeted prevention and early intervention. This analysis emphasizes the value of accessible clinical data in building predictive tools that can meaningfully support health equity and clinical decision-making.
Which features are most strongly associated with severe lung cancer?
Most Predictive Features:
-
Age (decreased accuracy by 19.8%)
-
Coughing up Blood (decreased by 11.1%)
-
Alcohol Usage (decreased by 9.6%)
-
Air Pollution (decreased by 8.6%)
Minimal Impact Features:
-
Sex (decreased by 0.1%)
-
Chest Pain
These insights highlight clinically relevant features and suggest future improvements to diagnostic screening tools.
Conclusion:
This project showed that a simple K-Nearest Neighbors model can effectively predict lung cancer severity using clinical and lifestyle data from Tikur Ambesa Hospital. The model achieved 95% accuracy and was especially strong in identifying high-risk cases. Key predictors included age, coughing up blood, alcohol use, and air pollution. These results support the use of interpretable ML tools to aid early detection and targeted intervention, particularly in low-resource healthcare settings.
Keywords:
Lung Cancer, KNN, Permutation Importance, Health Data, Ethiopia, Clinical Risk Factors, Public Health ML